


Websivujen juurihakemistossa on yleensä tiedosto robots.txt. Sen idea on, että sivuille saapuvat botit, spiderit ja crawlerit kävisivät lukemassa robots.txt tiedostosta saavatko ne tulla, mihin ne saavat mennä ja kuinka kova vauhti niillä saa olla. Robots.txt siis koskee kaikkia muita kuin ihmiskäyttäjiä. Ajatus on hieno, mutta se ei oikein toimi. Johtuu siitä, että robots.txt tiedoston lukeminen ja sen noudattaminen on täysin vapaaehtoista – se on siis kohtelias pyyntö ja kävijän käytöstavoista riippuu, että noudatetaanko pyyntö vai näytetäänkö keskisormea.
Tämä on asia, joka on ensimmäiseksi sisäistettävä: robots.txt ohjaa vain hyvinkäyttäytyviä botteja ja pahoille se enintään kertoo missä on sisältöä, jonka webmaster haluaisi piilottaa. Robots.txt ei suojaa mitään, eikä se liity mitenkään turvallisuuteen.
Tuo tarkoittaa kahta asiaa:
- bottien sisäänpääsyä on säädeltävä serverillä (Nginx ja Apache tekevät sen omilla tavoillaan), reverse proxyssä kuten Varnishissa tai viimeisenä oljenkortena .htaccess-tiedostossa
robots.txttiedostossa ohjataan vain ja ainoastaan niitä botteja, jotka päästetään sisään; siihen ei kerätä pitkää ja vielä pidempää listaa kaikista maailmassa tavatuista boteista
robots.txt tiedoston muoto
Robots.txt tiedoston syntaksi on yksinkertainen. Ensi kerrotaan käyttäjäagentin eli user agentin mukaan ketä säätö koskee ja sen jälkeen mitä saa tai ei saa tehdä.
https://gist.github.com/eksiscloud/e95dc3aa72ada44072dc88f0e1c7d755
robots.txt sääntöjen järjestyksellä on väliä, sillä niitä luetaan järjestyksessä. Jos kaikille boteille sallitut hakemistot kerrotaan heti alussa, niin myös myöhemmin estettävät botit noudattaisivat sitä ja jättäisivät piittaamatta myöhemmin tulevista säännöistä. Siksi listaan laitetaan ensin nimen mukaan, eli user agentilla, tehdyt säännöt ja vasta viimeiseksi kaikki koskevat.
Esimerkissä on ensin lueteltu nippu hyvinkäyttäytyviä, mutta sivustolle turhia, botteja. Sen jälkeen määräyksellä Disallow: / kielletään pääsy koko sivustolle. Nämä botit noudattaisivat kieltoa ja luopuisivat ideksoinnista. Jos botti ei löydä nimeään, niin se jatkaa alaspäin seuraavaan sääntöön.
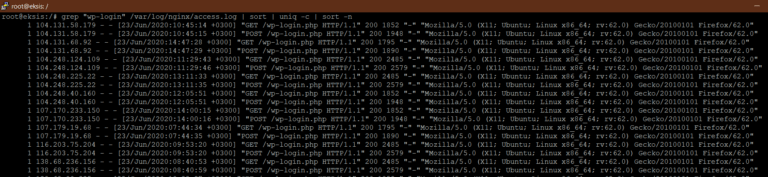
Seuraavaksi asteriskilla * kerrotaan, että kaikki seuraava koskee aivan jokaista bottia nimestä riippumatta. Ensin on kielletty WordPressin hallintaan liittyvä hakemisto wp-admin, mutta on sallittu käytölle tarpeellinen admin-ajax.php tiedosto. Samalla on kielletty kaksi muuta tiedostoa, wp-login.php ja xmlrpc.php.
Sitä vauhtia, jolla botti ryömii sivuston sisällä, voi periaatteessa säätää. Esimerkiksi
User-agent: bingbot Crawl-delay: 10
kertoo Bingin hakukonebotille, että se saa tehdä yhden sivupyynnön kerran 10 sekunnissa.
Ongelma on siinä, että suurin osa boteista ei piittaa crawl-delay säännöstä. Edes Google ei piittaa siitä. Suurimmalla osalla hakukoneita on webmastereille oma hallintasivu, jossa voi käydä kertomassa mm. sitemapin sijainti ja useimmissa voi myös ehdottaa botille hieman hitaampaa vauhtia, jotta koko koneteho ei hukkaantuisi botin palveluun. Muiden kohdalla on sitten aivan luojan huomassa (joka tarkoittaa toteuttaneen firman politiikkaa) noudatetaanko crawl-delay sääntöä tai ylipäätään yhtään mitään.
Sitemap
Sivuston sitemapin osoite voidaan kertoa aivan viimeisellä rivillä. Siihen ei tarvita muuta kuin täydellinen url, esimerkiksi
Sitemap: https://www.eksis.one/sitemap_index.xml
Hyöty on hieman kyseenalainen. Jokainen asiansa osaava webmaster käy kuitenkin kertomassa Googlen Search Consolessa sitemapin sijainnin. Saman voi tehdä Bingin, MSN:n ja muiden haluamiensa hakukoneiden palveluissa. Tai WordPress-käyttäjä asentaa toimivan SEO-palikan, kuten vaikka Rank Math SEO:n, ja antaa sen kertoa sitemapin osoitteen oleellisille hakukoneille.
Roboteille ja muille crawlereille on niiden oman toiminnan kannalta oleellisen tärkeää, että ne löytävät sisällön. Siksi luotto siihen, että etusivulta löytyisi riittävän kattavasti linkkejä, ei ole riittävä. Botit, crawlerit ja spiderit – Google, Bing jne. mukaanlukien – osaavat ominkin voimin kysäistä, että löytyykö sivuston juurihakemistosta sellaista kuin sitemap.xml.
Suurin osa fiksummista CMS-ohjelmista – joka automaattisesti tarkoittaa SEO-palikalla avustettua WordPressiä – osaa tehdä yhden keskitetyn index-tiedoston useammalle sitemapille, jotka koostetaan mm. sisältötyyppien suhteen. Sitä kutsutaan useimmiten nimellä sitemap_index.xml. Jotta helpottaisi hakukoneiden ja muiden bottien elämää, niin kannattaa tehdä 301 redirect osoitteesta /sitemap.xml osoitteeseen /sitemap_index.xml – tai mitä sitten nimenä käyttääkin.
Tosin, jos käytät yksinkertaisinta (ja toimivinta) mahdollista robots.txt muotoa, niin samalla vaivalla urlin sivustokartalle laittaa.
Honeypot
Koska pahantahtoiset robotit käyvät kurkkaamassa robots.txt tiedostosta onko ylläpitäjällä jotain suojeltuja hakemistoja, niin sitä saa hyödynnettyä yksinkertaisen hunajapurkin tekemiseen. Honeypot on tapa, jossa tehdään ihmiskäyttäjälle näkymätön sivu tai linkki, paikkaan, jonne botilla ei olisi asiaa. Jos joku saapuu linkin kautta, niin kyseessä on sääntöjä noudattamaton botti ja silloin logeista saadaan selville sen käyttämä user agent ja IP. Niillä saadaan sitten rakennettua esto vaikka Fail2bannin avulla.
Ajatus on kaunis ja joskus aikoinaan se varmaan toimikin. Nykyään botit lankeavat moiseen huomattavan harvoin, jos koskaan, ja ne jotka saa kiinni, jäisivät kiinni muutenkin. Mutta koska kyseessä on helppo ja vaivaton temppu, niin toki se kannattaa tehdä.
Annan esimerkin Nginxille ja Fail2bannille, mutta samalla tavalla se Apacheen tehdään.
Laita robots.txt tiedostoon joku houkutteleva hakemisto. Itse yritän triggeröidä ahneita ja olen nimennyt hakemiston nimellä private-wallet. Kiellä sinne pääsy boteilta.
User-agent: * Disallow: /private-wallet/
Tee hakemisto webserverin juurihakemistoon. Jos teet sen jonnekin muualle, niin muista laittaa oikea polku robots.txt tiedostoon.
Tee hakemistoon tiedosto. Itse jatkoin ahneiden provosointia ja nimesin sen nimellä wallet.html. Kopioi tämä tiedostoon:
<!DOCTYPE html> <html> <head> </head> <body> <h1>Secret area</h1> <p>Tämä on tarkoituksella tehty ansa paha-aikeisia botteja varten.</p> <p>Lomake ei liity mitenkään sivustoon.</p> <p>Älä yritä lähettää lomakkeella mitään. Jos kokeilet, niin suljet itsesi sivustolta. Jos kuitenkin yritit, niin lähetä sähköpostia ylläpidolle.</p> <form method='POST' action='bitcoin.php'> <input type='text' name='subject' value='154'> <input type='submit' value='submit'> </form> </body> </html>
Lomakkeen varoitus on suomeksi, koska en ole vielä koskaan tavannut bottia, joka ymmärtäisi suomea. Eivätkä ne muutenkaan varoituksiin readoisi.
Avaa Nginx:n virtual hostin conf-tiedosto ja lisää server lohkoon tämä:
location ~ /private-wallet/bitcoin\.php {
access_log /var/log/nginx/ban.log;
}
Avaa Fail2bannin jail.local ja kopioi sinne tämä:
[nginx-blocked] enabled = true port = 80,443 filter = nginx-blocked logpath = /var/log/nginx/blocked.log bantime = 3600 maxretry = 3 backend = auto findtime = 86400 banaction = iptables-multiport protocol = tcp chain = INPUT
Tee Fail2bannille filtteri nimellä nginx-blocked.conf:
[Definition] failregex = ^.* Blocked request from <HOST>.*$ ignoreregex =
Toiveena on, että pahatahtoinen botti kurkkaa robots.txt -tiedostosta minne ei saa mennä ja juurikin siksi menee. Koska monet rosvohommiin tehdyt botit pyrkivät aina ajamaan koodin, niin se yrittää lähettää lomakkeen ja liipaisee php-tiedoston. Silloin Nginx logittaa IP-osoitteen ja Fail2ban käyttää sitä bannaamiseen.
Rehellisesti sanottuna… en ole saanut tällä pyydystettyä koskaan yhtään mitään.
Yhteinen robots.txt eri domaineilla
Jos pyörität vain yhtä sivustoa, niin robots.txt tiedoston ylläpito on helppoa. Mutta jos sinulla on virtuaaliserveri ja useampi domain, niin jokainen muutos pitäisi muistaa tehdä jokaiselle domainille erikseen. Jos pystyt käyttämään samaa robots.txt tiedostoa kaikilla domaineilla, niin Apachella se on pikkuisen helpommin helposti toteutettu Nginxillä.
Käytännössä yhteistä robots.txt tiedostoa ei kannata käyttää. Se kannattaa pitää niin yksinkertaisena, että sitä ei tarvitse koskaan päivittää. Silloin saat mukaan myls urlin sitemapille.
Apache
Avaa apache2.conf:
nano /etc/apache2/apache2.conf
Kopioi tämä sinne tämä:
<Location "/robots.txt"> SetHandler None </Location> Alias /robots.txt /var/www/robots.txt
Tallenna käyttämäsi robots.txt hakemistoon /var/www. Poista kaikkien domainien webhakemiston juuresta robots.txt tiedostot.
Tarkista, ettei ole kirjoitusvirheitä ja käynnistä Apache2 uudestaan.
apache2ctl configtest
systemctl restart apache2
Nyt riittää, että ylläpidät yhtä robots.txt tiedostoa, joka ”näkyy” aivan kaikkien virtual hostien juurihakemistossa. Muista, että nyt et voi kertoa sitemapin sijaintia robots.txt tiedostossa, koska silloin kaikki osoittaisivat samaan.
Nginx
Nginx on hieman työläämpi, koska siinä ei pysty tekemään globaaleja aliaksia. Se tarkoittaa sitä, että joudut kertomaan jokaisessa virtual hostissa erikseen missä yhteinen robots.txt piileksii. Ei sekään mahdoton urakka ole. En ole kokeillut tätä, koska minulla homman hoitaa Apache, mutta pitäisi olla toimiva.
Avaa vhostin conf, esimerkiksi /etc/nginx/sites-available/example.com.conf ja lisää server osioon tämä:
location /robots.txt {
alias /var/www/robots.txt;
}
Tallenna käyttämäsi robots.txt hakemistoon /var/www. Poista kaikkien domainien webhakemiston juuresta robots.txt tiedostot.
Tarkista, ettei ole kirjoitusvirheitä ja lataa Nginx uudelleen:
nginx -t
systemctl reload nginx
Pidä robots.txt lyhyenä
Tuo kaikki tarkoittaa sitä, että robots.txt tiedoston suunnitteluun ei kannata käyttää kovinkaan paljon aikaa. Netti on täynnä ohjeita miten saadaan paras SEO-optimointi robots.txt tiedostolla – niiden sisältö on huuhaata ja jutut ovat vain oman sivustonsa SEO-markkinointia klikkaushuoraamisella ja ainoa tavoite on mainosnäytöt. On yksi ja vain yksi tapa, jolla saat syötyä hakukonenäkyvyytesi. Älä tee näin julkiselle sivustolle:
User-agent: * Disallow: /
Koska robots.txt ei estä bottien toimintaa kuin muutamassa harvassa tapauksessa ja niidenkin nimissä liikkuu huijausliikennettä, joka ei sääntöjä kunnioita, niin bottien estäminen per user-agent on ajanhukkaa. Samaten, kun päästät sisälle hyödylliset botit (ja ne. joita estosi ei pysäyttänyt), niin kunnolliset indeksoivat tismalleen samoja asioita kuin Google. Siksi et tarvitse kuin yksinkertaisimmat mahdolliset säännöt. Itseasiassa kielletyt hakemistot saat, ja kannattaakin, rajattua domainisi konfiguraatiossa, jolloin estät uteliaat ihmiset ja botit niin, että estoa ei kierretä.
Yksinkertaisin olisi tyhjä tiedosto nimellä robots.txt, jolloin et saa 404-ilmoituksia Googlelta ja parilta muulta ideksointibotilta. Tuo toki edellyttää, että hoidat homman virtual hostin conf-tiedostossa tai .htaccess-tiedostossa.
Tällä saat hoidettua perus-Wordpressin, muissa kannattaa säätää aidon tarpeen mukaan:
User-agent: * Disallow: /wp-admin/ Allow: /wp-admin/admin-ajax.php Sitemap: https://www.example.com/sitemap_index.xml
Keskustele foorumilla Katiskan foorumi